
- 非IC关键词
企业档案


产品分类


产品信息
深圳市惠新晨电子有限公司专注高性能高品质高性价比LED照明DC-DC宽电压输入降压恒流电源管理芯片市场,对LED照明市场有着深入的了解及丰富的经验,专注电源行业过10年,实力厂家,硬件设施齐全,工程资源充足,提供强大的技术支持,协助Lay板,调试直至产品可以大批量量产,以及帮忙过,提供样品、方案开发以及技术支持惠新晨电子备货实力强,可以做月结,是值得信赖合作的实力供应商
X30概述:
X30 是一款外围电路简洁低成本高性能的三通道线性降压LED恒流驱动器,适用于5-46V输入电压范围的LED 恒流照明领域。
X30 PWM 端口支持高辉调光,能够响应60ns小脉宽的PWM 调光信号。
X30采用我司算法,为客户提供解决方案,限度发挥灯具优势,以实现景观舞台灯高辉的调光效果,65535(256*256)级高辉调光。X30 PWM 端口为高电平时,芯片正常工作。为低电平时,芯片输出关闭。芯片采用线性恒流控制算法,只需两颗电阻与一颗电容,就能实现LED 恒流,且保证输出电流恒流精度≤±3%,通道之间电流偏差≤±1%;外围电路简洁,系统稳定可靠。
X30的三路输出电流都通过REXT 端口电阻来设定,电流能到350mA。而且,每一路电流能够独立进行PWM 高辉调光,实现65536:1 调光比。PWM 端口默认上拉,内部自带100uA 上拉能力
X30特点:
RGB调光无频闪/PWM调光无频闪
支持高辉调光,65536:1 调光比
输入电压范围:5-46V
三路分别独立恒流输出
每一路电流可达350mA
每一路独立PWM 调光
输出电流20~350mA
内置5V 稳压管
恒流精度≤3%
过温降电流降功率保护
易过EMI
抗干扰能力强
调光一致性好
封装:ESOP8
应用领域:
景观亮化LED 照明
DMX512 芯片外扩流应用
高端汽车车灯LED 照明
低压商业LED 照明
游戏机LED灯、儿童车灯、广告牌、广告招牌、珠宝装饰照明、背光源、软灯条等
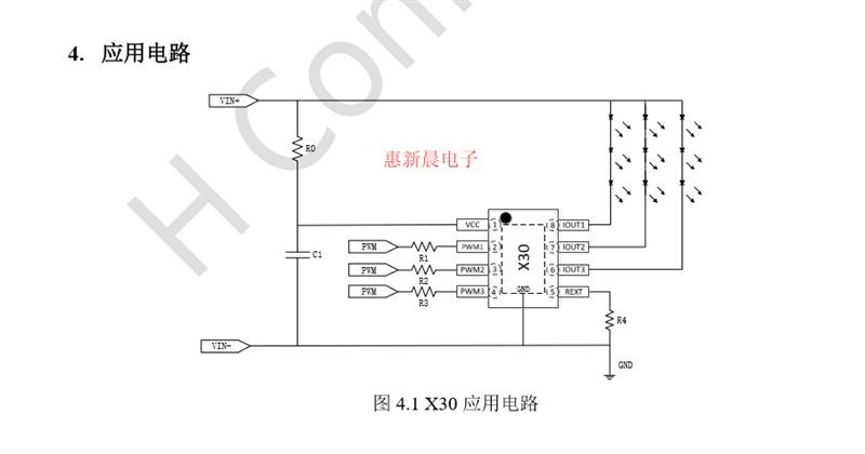
X30应用说明:
X30 是一款外围电路简单的多功能平均电流型LED 恒流驱动器,适用于5-46V 电压范围的低压线性恒流LED 驱动领域。X30 采用了LDO 线性恒流控制,外围不需要传统开关电源的电感和续流二极管,输出电流精度在±3%以内;外围电路更加简洁可靠。
惠新晨电子X30完全替代SM15133、SM15633 、SM1501、SM15122S、SM15102S、SM15103E、SM15133E、SM15105N、SM15633E、SM15106T,脚位一样,PIN对PIN完全兼容替代,无需改动任何元器件,调光效果更好,价格更优,性价比更高,欢迎申请样品测试,提供DEMO测试及技术支持
AI 突破性发展需要技术基础,也就是三驾马车,分别是算法 (Algorithms) 、大数据 (BigData) 、运算能力 (ComputePower) 。近年来, AI 的三驾马车已经取得长足发展。
1. 算法 (Algorithms) 变革与突破
从过去的神经网络开始,一直到近年的深度学习 (DeepLearning) ,尤其是多层神经网络技术飞速发展,算法进步让看似不可能的运算带入认知、拟人的学习推理领域。
早在 2015 年,微软 ResNet
系统采用 152 层的神经网络架构,让计算机对影像进行辨识并对物体开展检测,错误率降低到 3.5% ,正式越人类的 5.1% 水平;吴恩达先后在谷歌 x 实验室采用了参数多达 17 亿个的神经网络,在斯坦福大学做了更大的神经网络,采用参数多达 112 亿个神经网络。
人工神经元正在步步逼近人脑神经元,多层架构深度神经网络算法引起一阵风潮,复杂 AI 的算法正在迈入越人类认知水平的时代。
2. 大数据 (BigData) 数据库领域
巨量数据 / 大数据
(BigData) 伴随光纤、移动宽带网络普及、电商、物联网发展快速聚集,预计 2020 年数据量将过 40ZB ,相对 2010 年增长到
40 倍, 1ZB 数据意味着福斯电视 (FoxTV) 热门影集《 24 》连续播放 1.25 亿年,可见数据爆炸出想象;人们对数据结构化的技术推陈出新,如 NoSQL\MongoDB 等;通过良好的数据分类与标注,搭配搜索引擎与算法,让数据平台快速找到海量数据背后的隐藏的规律信息。
3. 运算能力
(ComputePower)
2012 年微软人工智能平台辨识单个猫需要 16000 颗传统 CPU 的运算能力才能达成,但类似的工作, 2016 年采用绘图芯片 GPU 大概只需要 2 颗。
就一个复杂棋局而言, AlphaGO 一代下一盘棋需要 1920CPUs 和 280GPUs ,同时有 64 个搜索线程; Alpha 第二代需要 50 个 TPU(1 个 TPU 算力大致相对于 10 个同级别 GPU) ;随着 AI
算力的大幅提升,算力仍然是 AI 的成本,据统计,算力成本
( 包括底层的硬件, GPU/CPU/FPGA 以及其他信号处理等半导体成本、能耗成本 ) 占 AI 成本在 70% 左右, AlphaGo 下一盘棋,其背后的服务器的总耗电量折算成电费是 3000 美元;计算的时大量耗热,通过吹风才能散热。算法、数据库基本可以实现平台化、软件化、工具化,边际成本趋向为 O ,决定 AI 普及的是算力和对应的能耗。
将算力低成本化,是 AI 与 IoT 融合并落地到具体场景,加速 AI 渗透到社会各角度,使能行业发展的关键,也是 AIoT 智联网规模发展的支点。其中,新出现的 AI 嵌入式芯片将 FPGA 发挥了主导作用。
AI 爆发之前,嵌入式芯片在物联网领域早已广泛应用,用于传感与智能硬件,通常采用 CPU 进行计算, CPU 特点兼顾计算和控制, 70% 晶体管用来构建 Cache 还有一部分控制单元,芯片设计用来处理复杂逻辑和提高指令的执行效率, CPU 计算通用性强,适用于处理计算复杂度高业务、串行数据处理,但计算性能一般。提升
CPU 性能需要增加 CPU 核数、提高 CPU 频率,或者修改 CPU 架构增加计算单元 FMA(fusedmultiply-add) 个数实现,提升算力同时也带来了高计算成本与能耗。
随着 AI 快速发展应用,尤其是图像处理数据量大,快速响应, CPU 不再是好的选择。 GPU 芯片逐渐成为深度神经网络 (DNN , DeepNeuralNetwork) 计算的主流。
GPU 特点是能够大幅精简
CPUCache 和逻辑控制单元,让出大量的计算单元。有限的尺寸中的晶体管更多用于计算,图形处理特点是算法本身复杂度低,计算强度高,数据之间相关性低特点, GPU 通过简单控制器,让数千计算单位执行相同程序,并行、流水化、高密度处理海量低关联数据,大幅提升数据计算、吞吐能力。
GPU 相对 CPU 更适合低层次大量重复运算领域,例如 AI 语音、视频、图片识别以及海量数据处理领域,不论是 CNN( 卷积神经网络 ) 、 RNN( 循环神经网络 ) 、还是 DNN( 深度神经网络 ) ,通过高强度类似蒙卡特罗实验计算,找出解,而无需复杂程度的运算。
可以说 GPU 在 AI 算力上比 CPU 有了大幅提升,每秒每瓦所执行的浮点运算达到 29G 次数 (29GFLOPS/W) ,是 CPU 的 3 倍多,能耗也随着提升,散热性与安全性成为问题。如下表 1 ;这也一定程度说明了 AI 的能耗成为不能承受之重
随着更多图像、视频和语音、物联网等非结构数据涌现,数据量继续急剧增长, AI 算法加速创新,不断加深神经网络层次,参数数量不断增多,模型算法复杂度持续提高,必然对计算带宽、内存带宽和存储要求越来越高,能耗成为很大问题。
更重要的是 GPU 内部架构通用,很难针对某个领域进行特殊优化,日新月异的物联、传感与 AI 行业应用要求芯片能够处理新类型的计算任务;在 GPU 之外如果没有新的嵌入式芯片选择, AI 无法随着 IoT 大规模落地到具体应用场景,无法与实体经济,生产生活紧密结合。
不同于 GPU 的运行原理, FPGA
是以门电路直接进行运算,硬件描述语言在执行时会被翻译成电路,也就是 FPGA 不采用指令和软件,是软硬件合一的器件。对 FPGA 进行编程仅仅使用硬件描述语言即可,硬件描述语言描述的逻辑可以直接被编译为晶体管电路的组合。所以 FPGA 实际上直接用晶体管电路实现用户的算法,没有通过指令系统的翻译。
在运算速度上, FPGA 由于算法是定制的,所以没有 CPU 和 GPU 的取指令和指令译码过程,数据流直接根据定制的算法进行固定操作,计算单元在每个时钟周期上都可以执行,所以可以充分发挥浮点计算能力,计算效率高于 CPU 和 GPU ,具有很大优势。
在功耗上,由于 FPGA 低延迟、低功耗的特性,近年来,微软、百度等公司在自家的数据中心里大量部署 FPGA ,百度在线上服务使用的 FPGA 版百度大脑,在同样的性能下,其功耗是天河二号级计算机的十分之一。